Start Indices Over Again After Dropping Rows From Pandas Dataframe
#pandas reset_index #reset alphabetize
pandas.reset_index in pandas is used to reset index of the dataframe object to default indexing (0 to number of rows minus ane) or to reset multi level index. By doing and so, the original index gets converted to a column.
By the cease of this article, you lot will know the different features of reset_index function, the parameters which can be customized to become the desired output from the function. This besides covers utilize cases that are closely related to doing reset index in pandas.
Want to master Data Science?
Get started with my free video courses (includes downloadable notebooks, projects and exercises)
Click to enroll into your free information science course
Showtime YOUR Costless Data Science Form
pandas.reset_index
Syntax
-
- pandas.reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill= ")
Purpose
-
- Reset the alphabetize, or a level of it. Reset the index of the DataFrame, and utilize the default one instead. If the DataFrame has a MultiIndex, this method can remove 1 or more than levels
Parameters
-
- level:
-
-
- int, str, tuple or list, (default None) Only remove the provided levels from the index. Removes all the levels past default.
-
-
- drib:
-
-
- bool, (default Fake) Do not add the old index into dataframe. By default, it adds.
-
-
- inplace:
-
-
- bool, (default False) Practise the changes in the current datafame object
-
-
- col_level:
-
-
- int or str, (default 0) If the columns accept multiple levels, determines at which level the labels are to exist inserted. Past default, it is inserted into the first level (0).
-
-
- col_fill:
-
-
- object, (default ") If the columns accept multiple levels, determines how the other levels are named. If None then the index name is repeated.
-
-
- level:
Returns
-
- DataFrame or None, DataFrame with the new index or None if inplace=True
1. How to reset the index?
To reset the alphabetize in pandas, you simply need to chain the function .reset_index() with the dataframe object.
Step i: Create a simple DataFrame
import pandas equally pd import numpy every bit np import random # A dataframe with an initial index. The marks represented here are out of 50 df = pd.DataFrame({ 'Networking': [45, 34, 23, 8, 21], 'Web Engineering': [32, 43, 23, 50, 21], 'Complier Design': [14, 42, 21, 12, 45] }, index=['Abhishek', 'Saumya', 'Ayushi', 'Saksham', 'Rajveer'] ) df 
Pace 2: Reset the index
df.reset_index() 
On applying the .reset_index() function, the index gets shifted to the dataframe as a divide column. It is named as index. The new index of the dataframe is now integers ranging from 0 to the length of the dataframe.
2. What happens if a named index is reset?
For dataframe with named index, then, the name of the alphabetize will be made as a cavalcade name in the dataframe, instead of the default proper name index. A named index means the alphabetize has a name assigned to it.
Step 1: Create a DataFrame with Named Index
# Create a Serial with name namedIndex = pd.Series(['Abhishek', 'Saumya', 'Ayushi', 'Saksham', 'Rajveer'], name='initial_index') # Create the dataframe and pass the named serial equally alphabetize df = pd.DataFrame({ 'Networking': [45, 34, 23, 8, 21], 'Web Applied science': [32, 43, 23, 50, 21], 'Complier Design': [fourteen, 42, 21, 12, 45] }, index=namedIndex ) df 
Pace ii: Reset the Alphabetize
Resetting the index in this instance returns a dataframe with initial_index equally the column name for the old index:-
df.reset_index() 
3. How to persist the change?
Consider a dataframe below, where the index has been reset:
# Create the dataframe df = pd.DataFrame({ 'Networking': [45, 34, 23, eight, 21], 'Spider web Engineering': [32, 43, 23, 50, 21], 'Complier Blueprint': [14, 42, 21, 12, 45] }, alphabetize=['Abhishek', 'Saumya', 'Ayushi', 'Saksham', 'Rajveer'] ) # reset the alphabetize df.reset_index() 
The output above shows that the alphabetize of the dataframe has been changed. But if you check the dataframe, it was not applied permanently:
df 
If you want your to retain your changes, then you demand to pass a parameter called inplace, and set it's value to Truthful, so that your index reset is applied to the dataframe object at the fourth dimension of running the reset_index function.
# reset the alphabetize with inplace=Truthful df.reset_index(inplace=Truthful) df 
4. How to driblet the one-time alphabetize?
You might exist interested in dropping the erstwhile index of the dataframe which was added while resetting the index. Though y'all can exercise this manually past using .drib() function, you lot can salve this fourth dimension by passing drop=Truthful parameter while resetting the index.
Step one: Create a DataFrame
df = pd.DataFrame({ 'Networking': [45, 34, 23, viii, 21], 'Web Engineering': [32, 43, 23, 50, 21], 'Complier Pattern': [14, 42, 21, 12, 45] }, index=['Abhishek', 'Saumya', 'Ayushi', 'Saksham', 'Rajveer'] ) df 
Step 2: Reset the alphabetize with drib=True
df.reset_index(drop=True) 
v. How to convert a column to an index?
You can reset the alphabetize of your dataframe without removing the default index by post-obit these steps:
Footstep ane: Create a DataFrame with initial index
df = pd.DataFrame({ 'Name': ['Abhishek', 'Saumya', 'Ayushi', 'Saksham', 'Rajveer'], 'Networking': [45, 34, 23, eight, 21], 'Spider web Technology': [32, 43, 23, 50, 21], 'Complier Pattern': [14, 42, 21, 12, 45], }, index=['One', 'Two', 'Three', '4', 'Five'] ) df 
Step 2: Gear up the column equally Index using set_index
# Set 'Name' equally the alphabetize of the dataframe df.set_index('Proper name', inplace=True) df 
6. How to reset multi-level index?
# Create a Multi-Level Index newIndex = pd.MultiIndex.from_tuples( [('IT', 'Abhishek'), ('IT', 'Rajveer'), ('CSE', 'Saumya'), ('CSE', 'Saksham'), ('EEE', 'Ayushi') ], names=['Branch', 'Proper noun']) # Optionally, you tin can also create multilevel columns columns = pd.MultiIndex.from_tuples( [('subject1', 'Networking'), ('subject2', 'Web Engineering'), ('subject3', 'Complier Pattern') ]) df = pd.DataFrame([ (45, 32, 14), (21, 21, 25), (23, 23, 21), (8, 50, 12), (34, 43, 42) ], alphabetize=newIndex, columns=columns) df 
Here you can see that Branch level maps to multiple rows. This is a multi-level index. Multi-level index shows the details in greater granularity, and they can exist very useful when we are dealing with hierarchical data.
If y'all apply the .reset_index() function to such type of dataframe, past default, all the levels will be merged into the dataframe as columns:
# convert multi-level index to columns. df.reset_index() 
Suppose, yous want to reset the alphabetize at Branch level. To reset such index, you lot need to provide the level parameter to the reset_index function.
df.reset_index(level='Branch') 
Name column notwithstanding remains as index. Considering we specified Branch as the level on which nosotros want to reset the index.
vii. Reset only one level in multi-level index
Consider our previous dataframe when information technology was reset at Branch level:
df.reset_index(level='Branch') 
You can meet that Branch column, on beingness reset, is placed at the meridian level(0) past default. Y'all tin alter this level by specifying col_level parameter.
It defines the level at which the shifted index cavalcade should exist placed. Look at an implementation below:
# Changing the level of cavalcade to i df.reset_index(level='Branch', col_level=one) 
8. How to fill void levels?
Continuing the previous example, you can run across that every bit the Branch cavalcade level has been lowered (level one), a void has been created at the level above it:
df.reset_index(level='Branch', col_level=1) 
You lot can make full this level likewise using col_fill parameter that takes in the proper noun for that.
df .reset_index(level='Co-operative', col_level=ane, col_fill='Department') 
ix. Practical Tips
.reset_index() function is very useful in cases when you take performed a lot of preprocessing steps with your data such as removing null values rows or filtering data.
These processes may return a different dataframe whose index is non in continuous way anymore. Let'southward try a modest example.
# Create a dataframe df = pd.DataFrame({ 'Name': ['Abhishek', 'Saumya', 'Ayushi', 'Ayush', 'Saksham', 'Rajveer'], 'Networking': [45, 34, 23, np.nan, 8, 21], 'Web Applied science': [32, 43, 23, np.nan, fifty, 21], 'Complier Design': [14, 42, 21, 14, 12, 45] }) df['Percentage'] = round((df.sum(axis=1)/150)*100, two) df 
# Drib null values df.dropna(centrality=0, inplace=True) # filter rows with percentage > 55 output = df[df.Percent > 55] output 
Equally you can see in the table above, the indexing of rows has inverse. Initially it was 0,1,2… but now it has inverse to 0,1,5.
In such cases, yous can apply .reset_index() office to number the rows in the right order.
# Set drop=Truthful if you don't want old index to be added as column output.reset_index(drop=True) 
10. Test your cognition
Q1: The pandas dataframe index is reset as soon as the .reset_index() role is practical to it. True or False?
Answer
Answer: False. Considering, the output dataframe is simply a view of the changes. To apply the changes, we use inplace parameter.
Q2: What is the use of drop parameter in .reset_index() office?
Answer
Respond: It is used to avert old index being added to pandas dataframe while resetting the alphabetize.
Q3: Which parameter is used change the default level of column while resetting multi-level index?
Respond
Answer: We use col_level parameter to define the level of cavalcade.
Q4: Respond the following questions using the given dataset.
import pandas as pd import numpy every bit np # Multi-Level Index newIndex = pd.MultiIndex.from_tuples( [('Information technology', 'Abhishek'), ('It', 'Rajveer'), ('MAE', 'Jitender'), ('CSE', 'Saumya'), ('CSE', 'Saksham'), ('CSE', 'Ayushi') ], names=['Branch', 'Proper noun']) # Multilevel columns columns = pd.MultiIndex.from_tuples( [('subject1', 'Figurer Graphics'), ('subject2', 'Artificial Intelligence'), ('subject3', 'Micro Processors') ]) df = pd.DataFrame([ (21, 21, 25), (45, 32, xiv), (viii, 50, 12), (23, 23, 21), (34, 43, 42), (42, 46, 21) ], index=newIndex, columns=columns) df['Pct'] = circular((df.sum(centrality=1)/150)*100, 2) df 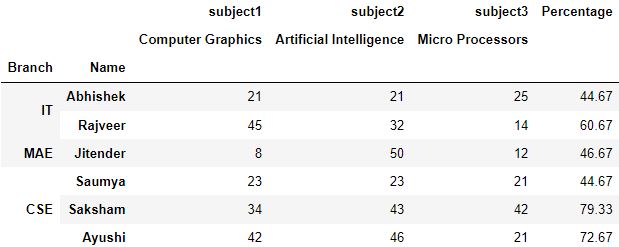
Q4.1: Reset the index at branch level, and assign an upper level Section for branch. Salve the output as ques1.
Answer
Reply:
# Make a copy of dataframe ques1 = df.copy() # Reset the alphabetize, ascertain the cavalcade level, name to fill in col_fill ques1.reset_index(level='Branch', col_level=1, col_fill='Department', inplace=Truthful) ques1 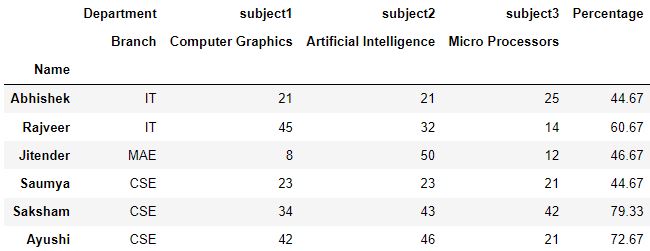
Q4.2: Use the output of Question 1 to add an upper level named Metric for Percentage. Make sure that name all the same remains the index
Answer
Reply:
# Make a copy of dataframe ques2 = ques1.re-create() # Reset the index so that names are shifted to dataframe as column ques2.reset_index(inplace=True) # Gear up the index as Percentage ques2.set_index('Percent', inplace=Truthful) # Reset the index with column level and col_fill defined ques2.reset_index(col_level=1, col_fill='Metric', inplace=Truthful) # Set the index again equally Name ques2.set_index('Proper noun') 
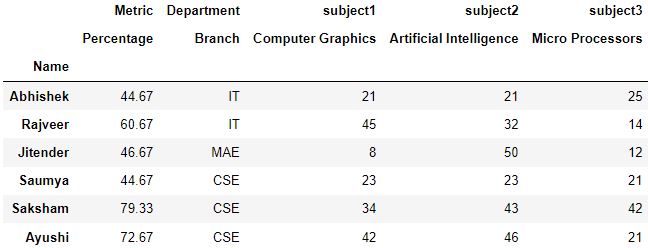
Q4.3: Calculate the rank of the students where branch is CSE and sorted in decreasing guild of Percentage. Print rank and name of educatee both.
Answer
Respond:
# make a copy of dataframe que3 = df.copy() # Reset the index que3.reset_index(inplace=True) # filter the rows by Branch, and then sort past Percentage in decreasing order output = que3[que3.Branch == 'CSE'].sort_values(by='Pct', ascending=False) # Reset the index output.reset_index(driblet=True, inplace=Truthful) print([(rank, name) for rank, name in cypher(output.alphabetize.values + 1, output.Proper name.values)]) 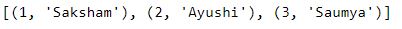
This blog has been contributed by Kaustubh Gupta, under the guidance of ML+ team.
Source: https://www.machinelearningplus.com/pandas/pandas-reset-index/
0 Response to "Start Indices Over Again After Dropping Rows From Pandas Dataframe"
Post a Comment